
I am having some problem related to Backpropogation. If we have a MLP, do we take the partial derivative on the latest layer and update the weight of the latest layer or we need to compute all of them to find the best weight of all layers. Also, how do we have the best learning rate when doing gradient decent? Thanks.
Hi, there is a dropdown in the B. Backpropagation section section called “Math to differentiate each part”, perhaps you can search for it to go through all the derivation. If that is to tough to understand let me draw you something that might help.
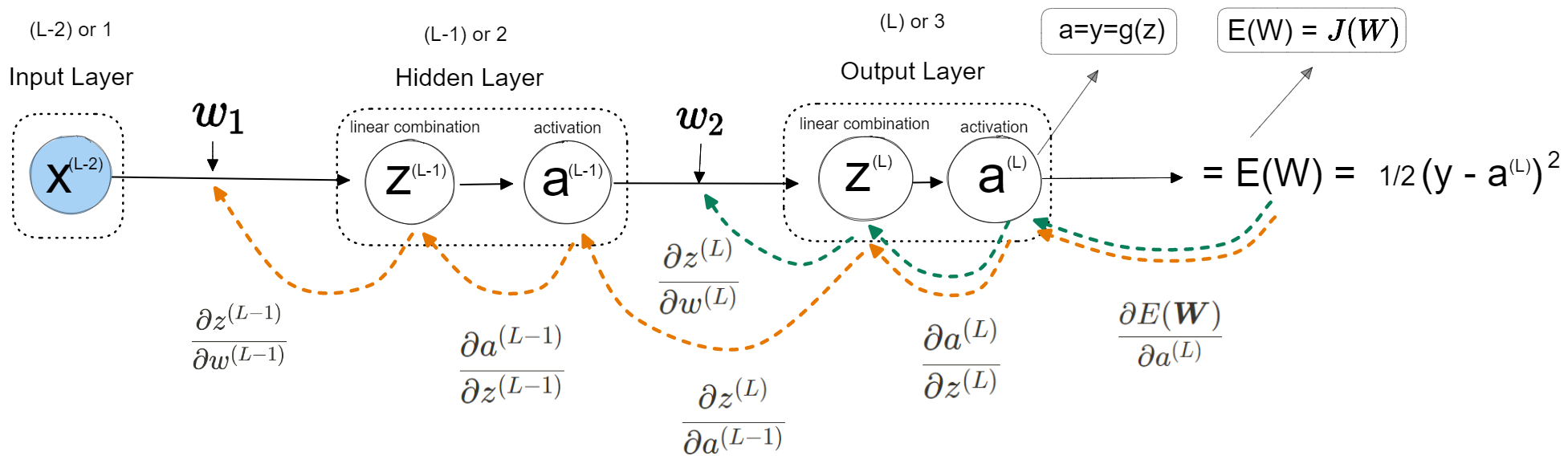
1 Like
And for your second question, there is no best learning rate, you just have to test a bunch of them, anything from 0.01 - 1 could work, you could start with something high and work your way down and see which gives you the best performance → at the end of the day it is a hyperparameter.
1 Like